
本文目录
背景
某公司旗下有多家门店,每个月会分批次把盘点数据向总公司汇报,汇报的数据量可能是亿级,并且每次汇报可能包含了上次汇报的修正数据,所以需要先根据主键去重,以最新的数据为准。
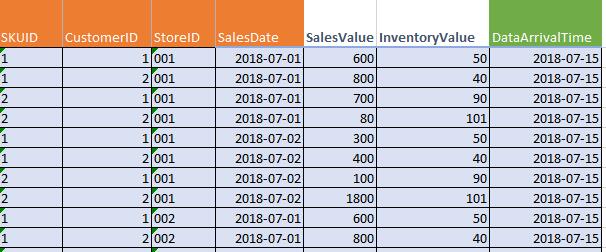
以上图为准,SKUID+CustomerId+StoreID+SalesDate红色的标题列为联合主键,再以绿色的列DataArrivalTime去重,取最新值。
最终需要生成所有门店的销售额报表,按照总销售额降序排列:
| StoreName | StoreId | TotalSales |
| 门店1 | 24 | 984756 |
| 门店2 | 56 | 982352 |
实践
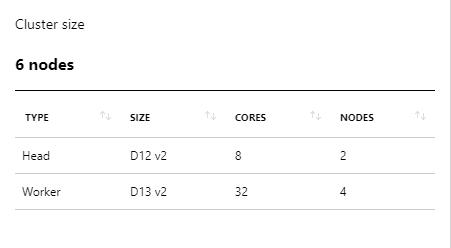
我们选择的环境是Azure上的HDInsight Spark 集群,配置如下:
通过Jupyter
新建PySpark3的Notebooks
导入基本类型
from pyspark.sql import SparkSession from pyspark.sql import * from pyspark.sql.types import * from pyspark.sql.window import Window from pyspark.sql.functions import rank, col from pyspark.sql import functions as func from pyspark.sql.functions import month,year,concat,format_string,desc
读取Azure Storage 中的csv文件
在jupyer中我们只读取一个小文件,用来测试
inputCsvDir="wasb:///directory/data/001.csv" df = spark.read.csv(inputCsvDir, header=True, inferSchema=True) df.show()
+-----+----------+-------+-------------------+----------+--------------+----------------+ |SKUID|CustomerID|StoreID| SalesDate|SalesValue|InventoryValue| DataArrivalTime| +-----+----------+-------+-------------------+----------+--------------+----------------+ | 32| 41| 55|2018-07-14 00:00:00| 924| 452|2018-07-19 09:42| | 31| 14| 38|2018-08-10 00:00:00| 4113| 4022|2018-08-12 15:55| | 27| 30| 12|2018-07-14 00:00:00| 1616| 8654|2018-07-23 00:04| | 26| 47| 24|2018-07-28 00:00:00| 957| 148|2018-08-11 16:32| | 48| 4| 81|2018-07-25 00:00:00| 3715| 2230|2018-07-30 22:01| | 9| 11| 40|2018-07-13 00:00:00| 2623| 6709|2018-07-25 07:01| | 45| 24| 28|2018-08-03 00:00:00| 3230| 7976|2018-08-06 05:50| | 23| 41| 83|2018-07-14 00:00:00| 807| 1629|2018-07-15 06:12| | 4| 22| 90|2018-07-21 00:00:00| 87| 9741|2018-08-12 12:59| | 31| 2| 18|2018-07-30 00:00:00| 4710| 3177|2018-08-02 04:40| | 10| 16| 9|2018-07-17 00:00:00| 2798| 799|2018-07-30 00:29| | 6| 4| 21|2018-07-19 00:00:00| 1666| 7970|2018-07-31 12:01| | 11| 38| 95|2018-07-20 00:00:00| 2960| 3131|2018-08-05 17:55| | 45| 15| 34|2018-07-21 00:00:00| 3637| 2487|2018-07-24 17:46| | 41| 28| 4|2018-07-24 00:00:00| 1702| 1725|2018-07-25 21:27| | 37| 3| 17|2018-07-18 00:00:00| 1884| 3904|2018-07-20 03:10| | 4| 25| 79|2018-07-23 00:00:00| 82| 7270|2018-07-25 10:42| | 26| 45| 48|2018-07-25 00:00:00| 165| 7630|2018-08-01 23:35| | 11| 7| 92|2018-07-18 00:00:00| 210| 9605|2018-07-23 05:17| | 17| 4| 34|2018-07-18 00:00:00| 3321| 6317|2018-07-28 07:13| +-----+----------+-------+-------------------+----------+--------------+----------------+ only showing top 20 rows
筛选所有8月份的数据
df = df.filter(df['SalesDate'] >= '2018-08-01') df.show()
+-----+----------+-------+-------------------+----------+--------------+----------------+ |SKUID|CustomerID|StoreID| SalesDate|SalesValue|InventoryValue| DataArrivalTime| +-----+----------+-------+-------------------+----------+--------------+----------------+ | 31| 14| 38|2018-08-10 00:00:00| 4113| 4022|2018-08-12 15:55| | 45| 24| 28|2018-08-03 00:00:00| 3230| 7976|2018-08-06 05:50| | 26| 22| 24|2018-08-09 00:00:00| 4186| 3988|2018-08-09 21:04| | 12| 16| 87|2018-08-06 00:00:00| 67| 3990|2018-08-10 10:00| | 47| 15| 49|2018-08-06 00:00:00| 2464| 6898|2018-08-07 04:44| | 12| 13| 26|2018-08-01 00:00:00| 254| 9929|2018-08-04 06:51| | 29| 7| 44|2018-08-03 00:00:00| 3133| 471|2018-08-07 04:42| | 28| 29| 27|2018-08-02 00:00:00| 4307| 6875|2018-08-04 05:17| | 39| 11| 71|2018-08-08 00:00:00| 2200| 5354|2018-08-12 19:53| | 39| 10| 14|2018-08-02 00:00:00| 4972| 5929|2018-08-03 11:22| | 21| 31| 99|2018-08-01 00:00:00| 3632| 795|2018-08-03 14:22| | 42| 8| 29|2018-08-04 00:00:00| 4389| 5532|2018-08-06 00:00| | 43| 18| 88|2018-08-04 00:00:00| 184| 26|2018-08-10 23:55| | 16| 27| 51|2018-08-03 00:00:00| 4754| 9556|2018-08-08 15:58| | 24| 2| 9|2018-08-04 00:00:00| 2456| 2521|2018-08-13 08:14| | 2| 3| 56|2018-08-06 00:00:00| 4868| 7167|2018-08-06 14:59| | 25| 32| 58|2018-08-01 00:00:00| 478| 4014|2018-08-02 14:19| | 15| 3| 91|2018-08-05 00:00:00| 676| 2703|2018-08-08 13:09| | 42| 7| 30|2018-08-02 00:00:00| 4742| 3251|2018-08-02 11:02| | 18| 1| 10|2018-08-01 00:00:00| 4388| 4730|2018-08-01 05:17| +-----+----------+-------+-------------------+----------+--------------+----------------+ only showing top 20 rows
使用window模式进行分组去重
window = Window.partitionBy(df['SKUID'],
df['CustomerID'],
df['StoreID'],
df['SalesDate']).orderBy(df['DataArrivalTime'].desc())
df = df.select('*', rank().over(window).alias('rank')).filter(col('rank') == 1)
df.show()
+-----+----------+-------+-------------------+----------+--------------+----------------+----+ |SKUID|CustomerID|StoreID| SalesDate|SalesValue|InventoryValue| DataArrivalTime|rank| +-----+----------+-------+-------------------+----------+--------------+----------------+----+ | 12| 12| 63|2018-08-05 00:00:00| 2650| 4982|2018-08-06 03:43| 1| | 15| 43| 76|2018-08-01 00:00:00| 4738| 3235|2018-08-10 20:08| 1| | 19| 47| 88|2018-08-08 00:00:00| 3832| 3907|2018-08-12 04:04| 1| | 22| 33| 62|2018-08-01 00:00:00| 1189| 5813|2018-08-06 09:41| 1| | 29| 12| 53|2018-08-04 00:00:00| 1898| 9908|2018-08-10 06:22| 1| | 37| 18| 47|2018-08-05 00:00:00| 3780| 2871|2018-08-05 17:04| 1| | 39| 16| 42|2018-08-08 00:00:00| 4292| 2447|2018-08-09 06:25| 1| | 45| 24| 28|2018-08-03 00:00:00| 3230| 7976|2018-08-06 05:50| 1| | 3| 15| 52|2018-08-07 00:00:00| 4591| 4182|2018-08-10 17:55| 1| | 10| 13| 83|2018-08-04 00:00:00| 2391| 3459|2018-08-04 16:50| 1| | 10| 13| 95|2018-08-03 00:00:00| 823| 4463|2018-08-12 19:43| 1| | 21| 8| 25|2018-08-07 00:00:00| 4242| 4829|2018-08-12 22:30| 1| | 44| 42| 83|2018-08-01 00:00:00| 2878| 8283|2018-08-11 05:30| 1| | 1| 17| 34|2018-08-08 00:00:00| 3511| 5744|2018-08-11 05:35| 1| | 9| 11| 8|2018-08-04 00:00:00| 577| 1151|2018-08-11 16:13| 1| | 14| 2| 24|2018-08-04 00:00:00| 3917| 8689|2018-08-11 12:57| 1| | 6| 32| 71|2018-08-02 00:00:00| 3871| 4069|2018-08-06 22:59| 1| | 39| 32| 23|2018-08-02 00:00:00| 1026| 7535|2018-08-05 01:20| 1| | 2| 49| 92|2018-08-01 00:00:00| 1588| 8685|2018-08-06 00:00| 1| | 11| 30| 69|2018-08-08 00:00:00| 455| 9936|2018-08-11 01:33| 1| +-----+----------+-------+-------------------+----------+--------------+----------------+----+ only showing top 20 rows
根据门店分组,并汇总销售额
monthlyByStore = df.groupby('StoreID') \
.agg(func.sum("SalesValue").alias('TotalSales'))
monthlyByStore = monthlyByStore.orderBy(monthlyByStore['TotalSales'].desc())
monthlyByStore.show()
+-------+----------+ |StoreID|TotalSales| +-------+----------+ | 24| 38385| | 52| 34762| | 93| 33797| | 76| 32639| | 74| 31924| | 9| 31417| | 87| 31315| | 45| 31020| | 44| 31019| | 35| 30973| | 1| 30017| | 20| 29777| | 83| 28589| | 95| 28324| | 22| 27589| | 38| 27538| | 2| 27318| | 21| 27191| | 56| 26657| | 62| 26612| +-------+----------+ only showing top 20 rows
读取门店维度表,Join门店名称
dfStoreData = spark.read.csv("wasb:///cat-big-data-0.2billion/storageData.csv", header=True, inferSchema=True)
monthlyByStoreWithName = monthlyByStore.join(dfStoreData,dfStoreData['StoreID']==monthlyByStore['StoreId'],'left')
monthlyByStoreWithName = monthlyByStoreWithName.select('StoreName',dfStoreData['StoreId'],'TotalSales')
monthlyByStoreWithName.show()
+---------+-------+----------+ |StoreName|StoreId|TotalSales| +---------+-------+----------+ | 24号门店| 24| 38385| | 52号门店| 52| 34762| | 93号门店| 93| 33797| | 76号门店| 76| 32639| | 74号门店| 74| 31924| | 9号门店| 9| 31417| | 87号门店| 87| 31315| | 45号门店| 45| 31020| | 44号门店| 44| 31019| | 35号门店| 35| 30973| | 1号门店| 1| 30017| | 20号门店| 20| 29777| | 83号门店| 83| 28589| | 95号门店| 95| 28324| | 22号门店| 22| 27589| | 38号门店| 38| 27538| | 2号门店| 2| 27318| | 21号门店| 21| 27191| | 56号门店| 56| 26657| | 62号门店| 62| 26612| +---------+-------+----------+ only showing top 20 rows
保存结果至Hive表
monthlyByStoreWithName.write.mode("overwrite").saveAsTable("hv_monthly_report")
通过Hive View查询
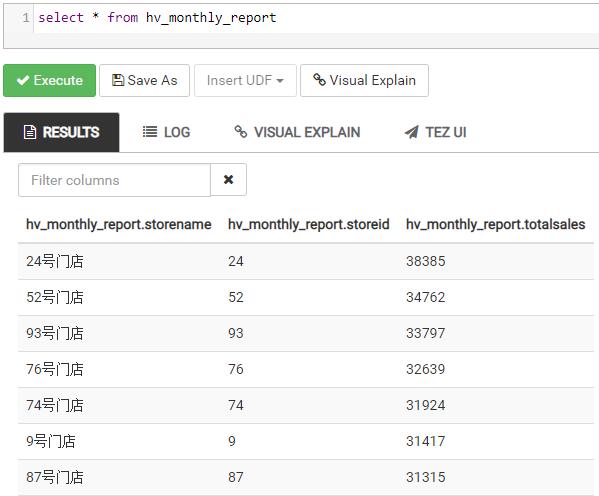
hive viewer 查询结果
通过Livy Job
将上述的脚本片段保存成Python脚本sales-report.py文件,并上传至Azure存储账户,然后通过livy 的REST 提交 Spark submit Job
编写脚本文件
from pyspark.sql import SparkSession
from pyspark.sql import *
from pyspark.sql.types import *
from pyspark.sql.window import Window
from pyspark.sql.functions import rank, col
from pyspark.sql import functions as func
from pyspark.sql.functions import month,year,concat,format_string,desc
#
# init Spark session
#
spark = SparkSession \
.builder \
.appName("Build Monthly Sales Data Report") \
.enableHiveSupport() \
.getOrCreate()
# read csv input
inputCsvDir="wasb:///directory/data/*.csv"
df = spark.read.csv(inputCsvDir, header=True, inferSchema=True)
# filter latest month
df = df.filter(df['SalesDate'] >= '2018-08-01')
# remove duplicate rows
window = Window.partitionBy(df['SKUID'],
df['CustomerID'],
df['StoreID'],
df['SalesDate']).orderBy(df['DataArrivalTime'].desc())
df = df.select('*', rank().over(window).alias('rank')).filter(col('rank') == 1)
# group by store
monthlyByStore = df.groupby('StoreID') \
.agg(func.sum("SalesValue").alias('TotalSales'))
monthlyByStore = monthlyByStore.orderBy(monthlyByStore['TotalSales'].desc())
# join wth store name#
dfStoreData = spark.read.csv("wasb:///directory/storeData.csv", header=True, inferSchema=True)
monthlyByStoreWithName = monthlyByStore.join(dfStoreData,dfStoreData['StoreID']==monthlyByStore['StoreId'],'left')
monthlyByStoreWithName = monthlyByStoreWithName.select('StoreName',dfStoreData['StoreId'],'TotalSales')
# save result to hive table
monthlyByStoreWithName.write.mode("overwrite").saveAsTable("hv_monthly_report")
提交 Livy Job
curl -k --user 'admin:password' -v -H 'Content-Type: application/json' -X POST
-d '{ "file": "wasb:///directory/sales-report.py", "args": [""]}' "https://xxx.azurehdinsight.net/livy/batches"
-H "X-Requested-By: admin"
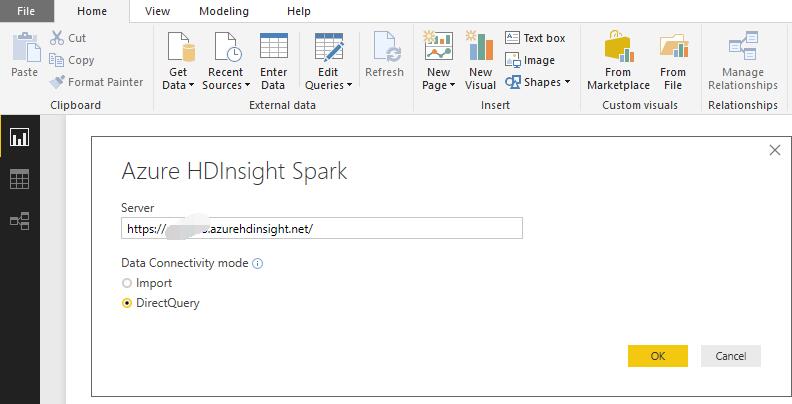
Power BI 中连接HD insight
备注:如何在Power BI中生成报表不是本篇重点,这里主要是演示其可行性


本文链接: https://www.pstips.net/build-sales-report-based-on-hdinsight.html
请尊重原作者和编辑的辛勤劳动,欢迎转载,并注明出处!
请尊重原作者和编辑的辛勤劳动,欢迎转载,并注明出处!